Power, Exponential, and Logistic Regression via Pseudoinverse
Transforming nonlinear functions so that we can fit them using the pseudoinverse.
This post is part of the book Introduction to Algorithms and Machine Learning: from Sorting to Strategic Agents. Suggested citation: Skycak, J. (2022). Power, Exponential, and Logistic Regression via Pseudoinverse. In Introduction to Algorithms and Machine Learning: from Sorting to Strategic Agents. https://justinmath.com/power-exponential-and-logistic-regression-via-pseudoinverse/
Want to get notified about new posts? Join the mailing list and follow on X/Twitter.
Previously, we learned that we can use the pseudoinverse to fit any regression model that can be expressed as a linear combination of functions. Unfortunately, there are a handful of useful models that cannot be expressed as a linear combination of functions. Here, we will explore $3$ of these models in particular.
The techniques that we will learn for fitting these models will apply more generally to any model that can be transformed into a linear combination of functions (where the parameters are the coefficients in the linear combination).
Power and Exponential Regressions
Power and exponential regressions are familiar algebraic functions, so we will address them first. To transform a power or exponential regression into a linear combination of functions, we can transform the equation by taking the natural logarithm of both sides and applying the laws of logarithms to pull apart the expression on the right-hand side:
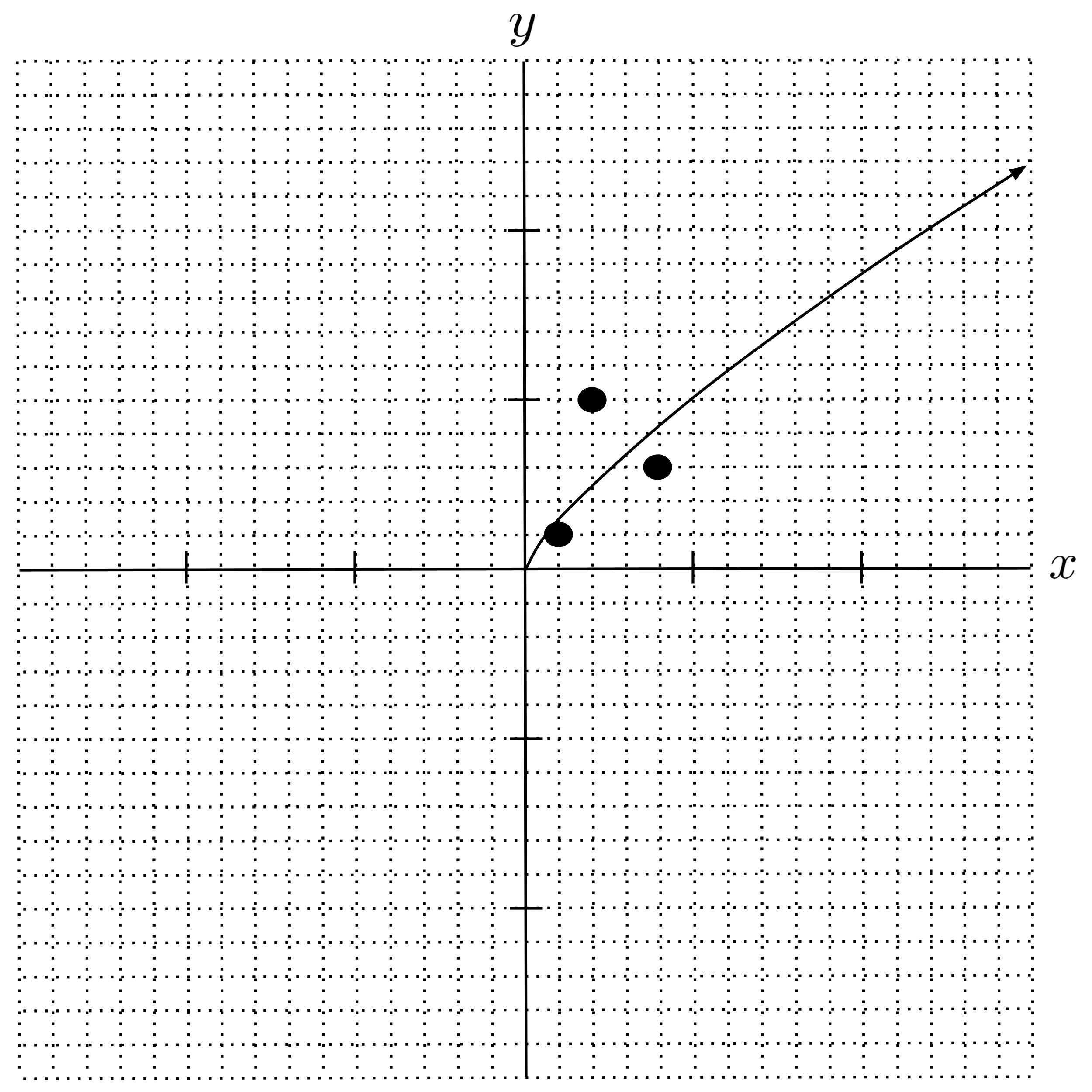
Let’s fit the power regression to the following data set.
As usual, we set up the system of equations, convert it into a matrix equation, and apply the pseudoinverse.
So, we have the following model:
By combining the logarithms and reversing the transformation that we originally applied to the power regression $y = a \cdot x^b,$ we can write the above model in power regression form:
Danger: Unintentional Domain Constraints
Notice that the data set we used above was slightly different from the data set that we’ve used earlier in this chapter. We changed the $x$-coordinate $0$ to a $1$ in the first data point.
The reason why we modified the data set is that the earlier data set exposes a limitation of the pseudoinverse method. We can’t fit our power regression model to the earlier data set, because the $x$-coordinate of $0$ causes a catastrophic issue in our transformed power regression equation.
To see what the issue is, let’s substitute the point $(0,1)$ into our transformed power regression equation and see what happens:
The quantity $\ln 0$ is not defined, so $0$ is not a valid input for $x.$ By transforming the equation, we unintentionally imposed a constraint on the valid inputs $x.$
Danger: Suboptimal Fit
Unfortunately, this is not the only bad news. Even with our new data set, which does not contain any points with an $x$-value of $0,$ the pseudoinverse did not give us the most accurate fit of the power regression $y = ax^b.$ It gave us the most accurate fit of the transformed model $\ln y = (\ln a) \cdot 1 + b \cdot \ln x,$ but this is not the most accurate fit of the original power regression even though the two equations are mathematically equivalent.
To understand this more clearly, let’s consider an extreme example. If we were to fit a power regression to the data set
using the same method that we demonstrated above, then we would get the following model:
However, if we plot this curve along with the data, then it’s easy to see that this is not the most accurate model. It doesn’t even curve the right way! A hand-picked model as simple as $y = x^2$ would be vastly more accurate.
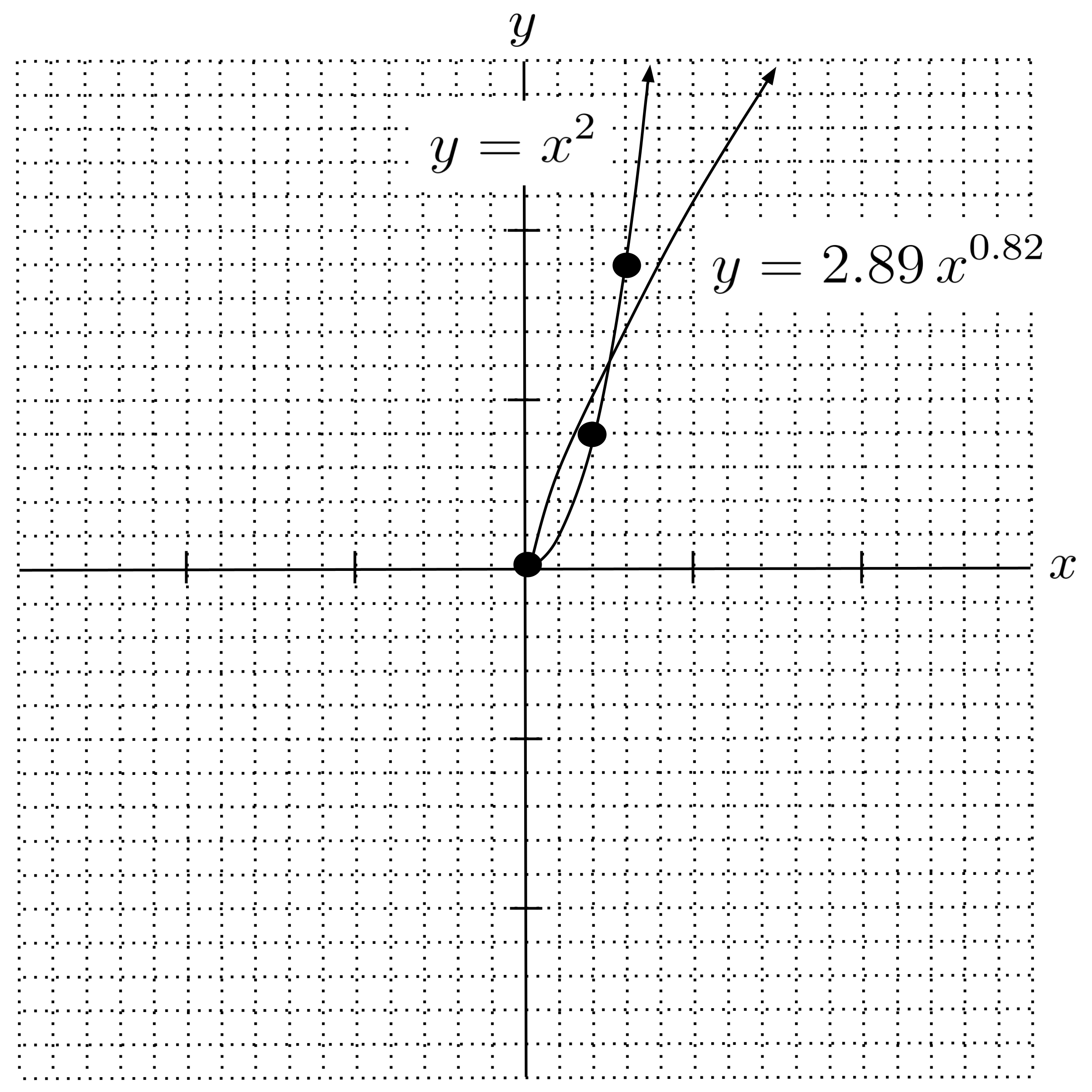
The reason the pseudoinverse method gave us an inaccurate model is that we transformed the model and data into a different space before we applied the pseudoinverse:
In the space that the data was transformed to, it turns out that the model $y \approx 2.89 \, x^{0.82}$ is more accurate than the model $y=x^2.$ To visualize this, we can plot these two models along with the data in the space of points $(\ln x, \ln y).$
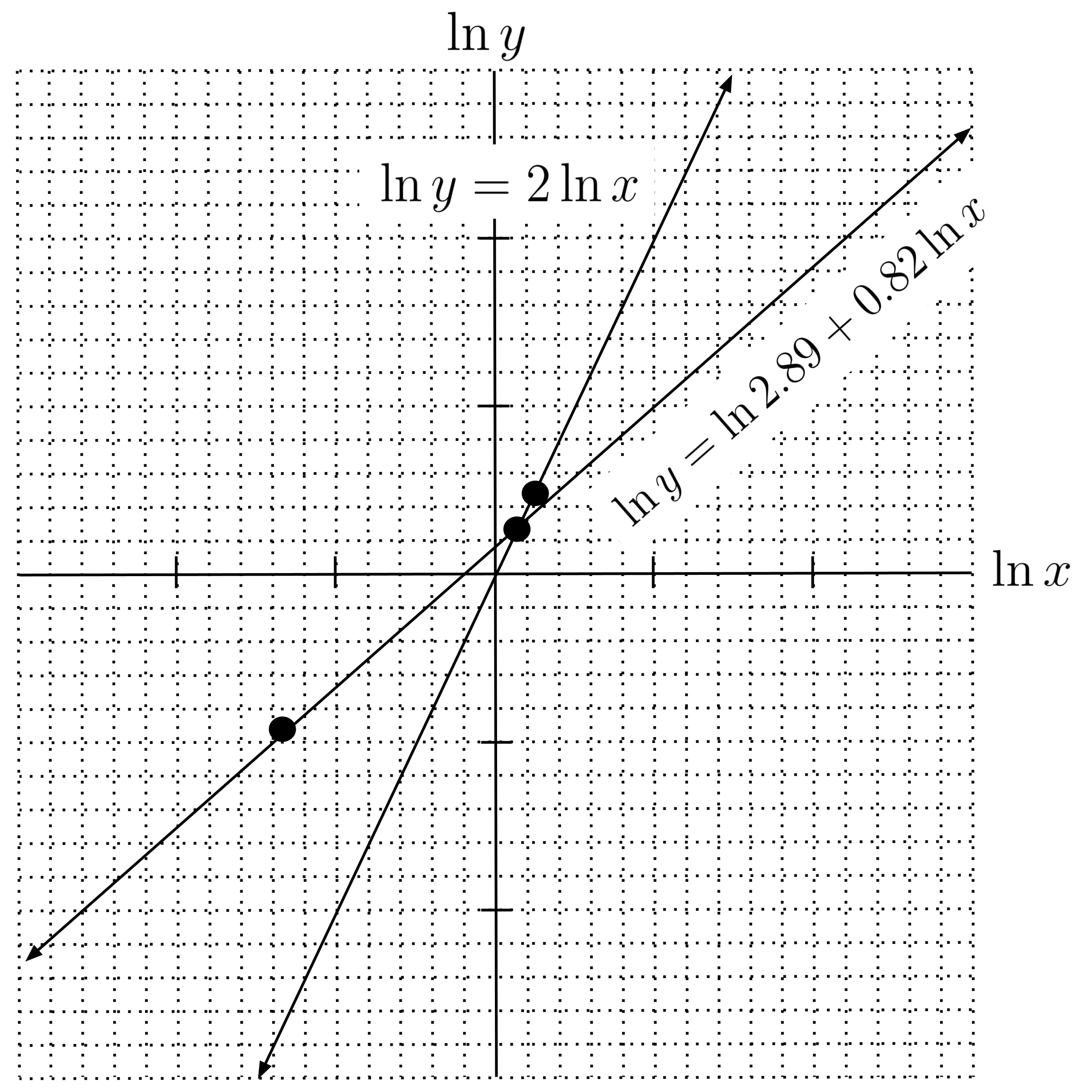
Indeed, $\ln y = \ln 2.89 + 0.82 \ln x$ is the most accurate model in the space of points $(\ln x, \ln y),$ but it is not the most accurate model in the space of points $(x,y).$
This is something to be cautious of whenever you transform a model into a space where the pseudoinverse can be applied – you should always check the function afterwards and verify that it is looks accurate “enough” for your purposes.
Logistic Regression
Soon, we will learn about other methods of fitting models that are robust to this sort of issue. But for now, let’s end by discussing the logistic function:
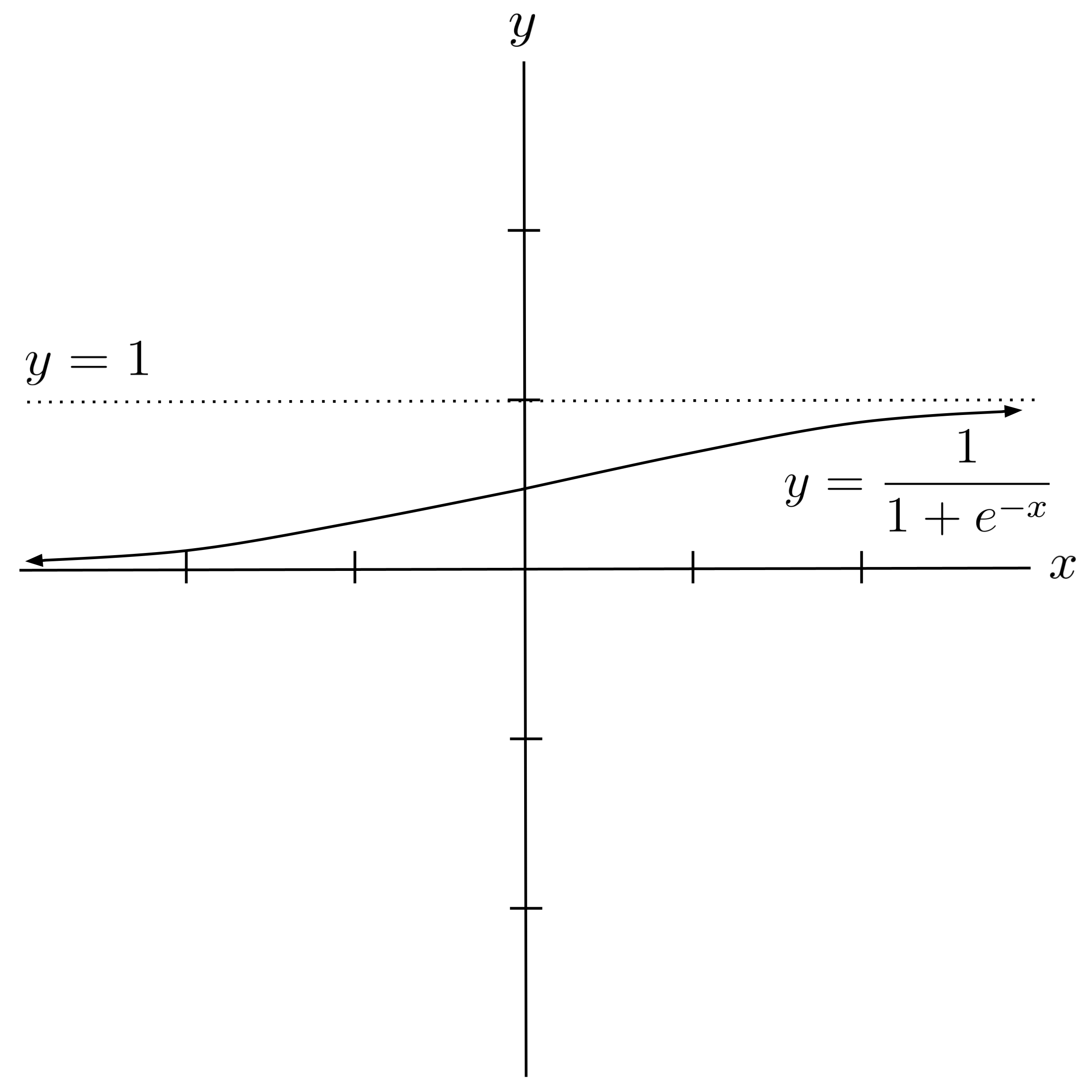
The logistic function has a range of $0 < y < 1,$ and it is a common choice of model when the goal is to predict a bounded quantity. For example, probabilities are bounded between $0$ and $1,$ and rating scales (such as movie ratings) are often bounded between $1-5$ and $1-10.$
Let’s construct a real-life scenario in which to fit a logistic regression. Suppose that a food critic has rated sandwiches on a scale of $1-5$ as follows:
- A roast beef sandwich with $1$ slice of roast beef was given a rating of $1$ out of $5.$
- A roast beef sandwich with $2$ slices of roast beef was given a rating of $1$ out of $5.$
- A roast beef sandwich with $3$ slices of roast beef was given a rating of $2$ out of $5.$
We will model the food critic’s rating as a function of the number of slices of roast beef. Our data set will consist of points $(x,y),$ where $x$ represents the number of slices of roast beef and $y$ represents the food critic’s rating.
To model the rating, we can fit a logistic function and then round the output to the nearest whole number. Since the rating scale is between $1-5$ and we are going to round the output of the logistic function, we need to construct a logistic function with the range $0.5 < y < 5.5.$ We can do this as follows:
So, our goal is to fit the following model to the data set $[(1,1), (2,1), (3,2)].$
In order to fit the model using the pseudoinverse, we need to transform it into a linear combination of functions. We do so by manipulating the equation to isolate the $ax+b{:}$
Now, we can proceed with the usual process of fitting our model using the pseudoinverse.
So, we have the following model:
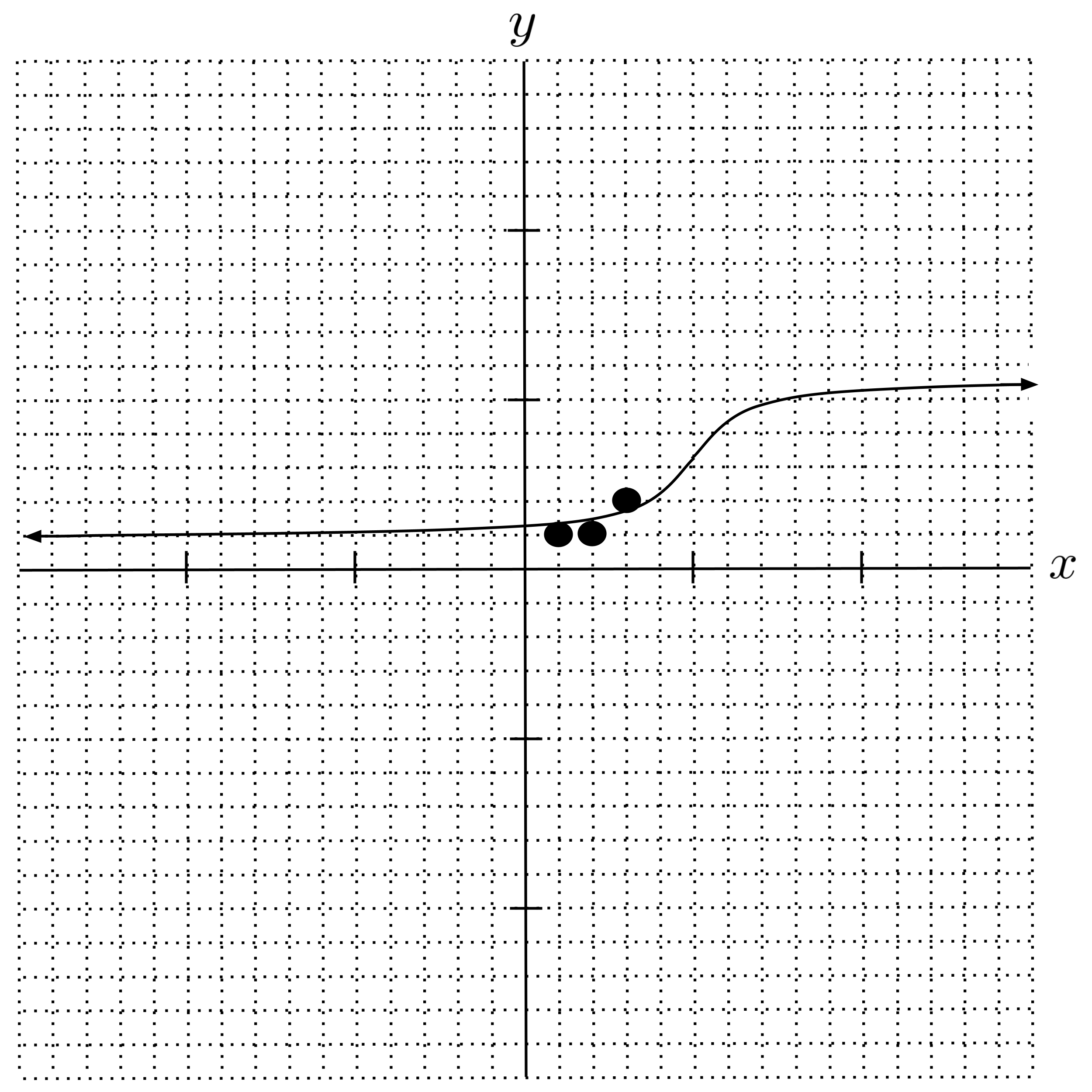
Since we had to transform the model into a space where the pseudoinverse can be applied, we need to check the function and verify that it looks accurate enough for our purposes. Here, our regression curve looks fairly accurate, so we will proceed to analyze it.
Now that we have a regression curve, we can use it to make predictions about the data. For example, what rating would we expect the critic to give a sandwich with $6$ slices of roast beef? To answer this question, we just plug $x=6$ into our model:
Our result of $4.08$ rounds to $4.$ So, according to our model, we predict that the critic would give a rating of $4$ to a sandwich that had $6$ slices of roast beef.
Exercises
Use the pseudoinverse method to fit each model to the given data set. Check your answer each time by sketching the resulting model on a graph containing the data points and verifying that it visually appears to capture the trend of the data.
- Fit a power regression $y = a \cdot x^b$ to $[(1,0.2), (2,0.3), (3,0.5)].$
- Fit an exponential regression $y = a \cdot b^x$ to $[(1,0.2), (2,0.3), (3,0.5)].$
- Fit a logistic regression $y = \dfrac{1}{1+e^{-(ax+b)}}$ to $[(1,0.2), (2,0.3), (3,0.5)].$
- Construct a logistic regression whose range is $0.5 < y < 10.5$ and fit it to $[(1,2), (2,3), (3,5)].$
This post is part of the book Introduction to Algorithms and Machine Learning: from Sorting to Strategic Agents. Suggested citation: Skycak, J. (2022). Power, Exponential, and Logistic Regression via Pseudoinverse. In Introduction to Algorithms and Machine Learning: from Sorting to Strategic Agents. https://justinmath.com/power-exponential-and-logistic-regression-via-pseudoinverse/
Want to get notified about new posts? Join the mailing list and follow on X/Twitter.