Regression via Gradient Descent
Gradient descent can help us avoid pitfalls that occur when fitting nonlinear models using the pseudoinverse.
This post is part of the book Introduction to Algorithms and Machine Learning: from Sorting to Strategic Agents. Suggested citation: Skycak, J. (2022). Regression via Gradient Descent. In Introduction to Algorithms and Machine Learning: from Sorting to Strategic Agents. https://justinmath.com/regression-via-gradient-descent/
Want to get notified about new posts? Join the mailing list and follow on X/Twitter.
Gradient descent can be applied to fit regression models. In particular, it can help us avoid the pitfalls that we’ve experienced when we attempt to fit nonlinear models using the pseudoinverse.
Previously, we fit a power regression $y = ax^b$ to the following data set and got a result that was quite obviously not the most accurate fit.
This time, we will use gradient descent to fit the power regression and observe that our resulting model fits the data much better.
Model-Fitting as a Minimization Problem
To fit a model using gradient descent, we just have to construct an expression that represents the error between the model and the data that it’s supposed to fit. Then, we can use gradient descent to minimize that expression.
To represent the error between the model and the data that it’s supposed to fit, we can use the residual sum of squares (RSS). To compute the RSS, we just add up the squares of the differences between the model’s predictions and the actual data.
Summing up the squared differences between the predicted $y$-values and the $y$-values in the data, we get the following expression for the RSS:
Now, this is a normal gradient descent problem. We choose an initial guess for $a$ and $b$ and then use the partial derivatives $\frac{\partial \textrm{RSS}}{\partial a}$ and $\frac{\partial \textrm{RSS}}{\partial b}$ to repeatedly update our guess so that it results in a lower RSS.
Computing partial derivatives, we have the following:
Worked Example
Let’s start with the initial guess $\left< a_0, b_0 \right> = \left< 1, 1 \right>,$ which corresponds to the straight line $y = 1x^1.$ Our gradient is
and using learning rate $\alpha = 0.001$ our updated guess is
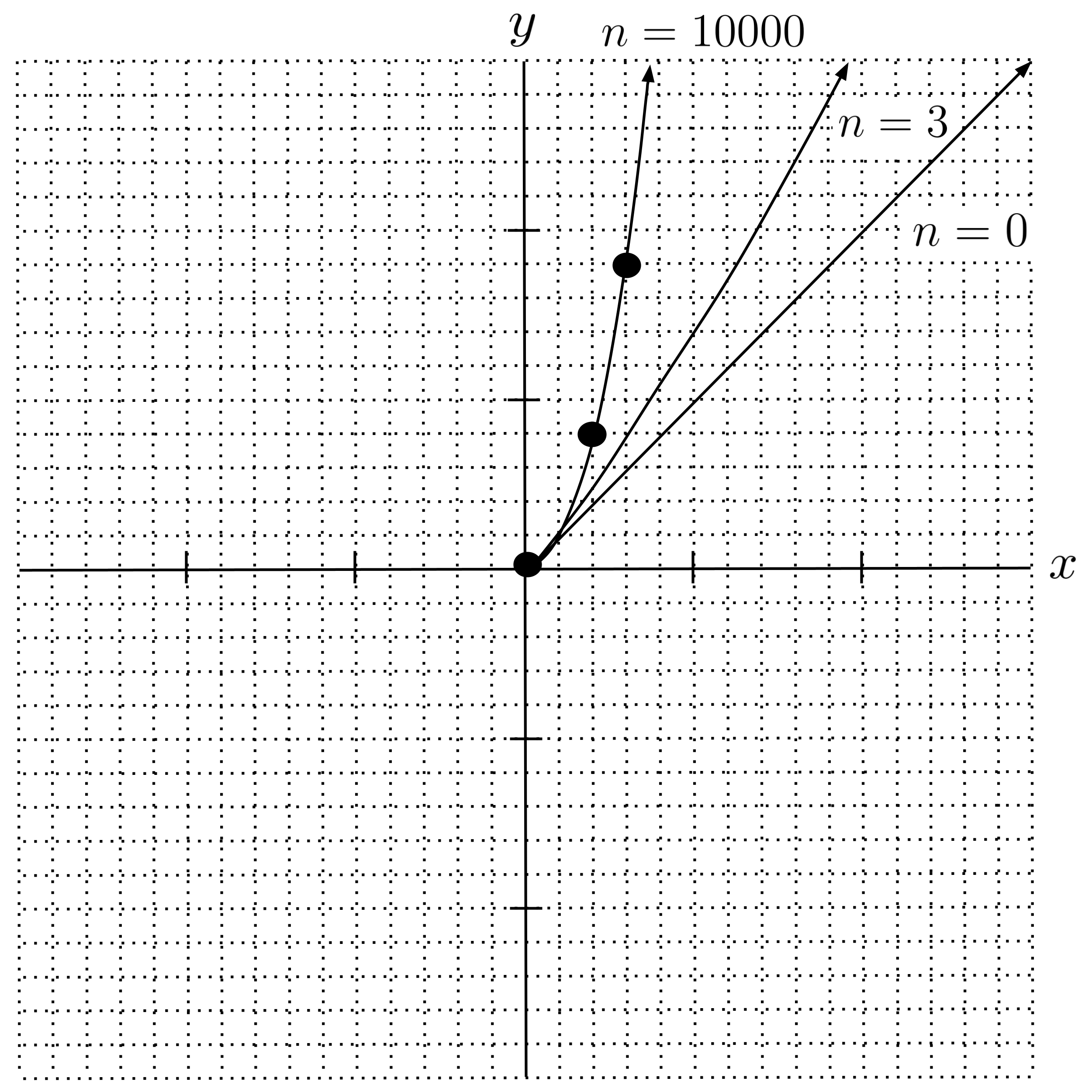
If we continue the process, we get the results shown in the table below.
Our gradient descent converged to $a=1$ and $b=2,$ which corresponds to the function $y = 1x^2.$ As we can see from the graph below, this is a very good fit.
Sigma Notation and Implementation
Note that when implementing gradient descent on a data set consisting of more than a few points, it becomes infeasible to hard-code the entire expression for the RSS gradient. Instead, it becomes necessary to write a function that loops through the points in the data set and incrementally adds up each point’s individual contribution to the total RSS gradient. It also becomes convenient to re-use intermediate values when possible.
To think through this, it’s helpful to express the RSS and its gradient using sigma notation. In the example above, the RSS is given by
and its gradient is computed as
Now that we’ve worked out the sigma notation, we can write a function that mirrors it:
gradRSS(a, b, data):
da = 0
db = 0
for (x,y) in data:
common = 2 * (ax^b - y) * x^b
da += common
db += common * a * b * x^-1
return da, db
Debugging with Central Difference Quotients
Lastly, note that when debugging broken gradient descent code, it can be helpful to check your partial derivatives against difference quotient approximations to ensure that you’re computing the partial derivatives correctly:
where $0 < h \ll 1$ is a small positive number.
Do not abuse difference quotients and attempt to use them to fully bypass gradient computations. Use difference quotients only for debugging. Difference quotients will be too slow to effectively train more advanced models (such as neural networks), and it’s useful to practice gradient computations on simpler models before moving on to more advanced models.
Exercises
Use gradient descent to fit the following models. Be sure to plot your model on the same graph as the data to ensure that the fit is looks reasonable.
- Implement the example that was worked out above.
- Fit $y = ax^2 + bx + c$ to $\left[ (0.001, 0.01), (2,4), (3,9) \right].$ Verify that gradient descent gives the same fit as compared to using the pseudoinverse.
- Fit $y = \dfrac{5}{1+e^{-(ax+b)}} + 0.5$ to $[(1,1), (2,1), (3,2)].$ Verify that gradient descent gives a better fit as compared to using the pseudoinverse.
- Fit $y = a \sin bx + c \sin dx$ to
$\begin{align*} \begin{bmatrix} \left(0,0\right), & \left(1,-1\right), &\left(2,2\right), &\left(3,0\right), &\left(4,0\right) \\ \left(5,2\right), &\left(6,-4\right), &\left(7,4\right), &\left(8,1\right), &\left(9,-3\right) \end{bmatrix}. \end{align*}$
This post is part of the book Introduction to Algorithms and Machine Learning: from Sorting to Strategic Agents. Suggested citation: Skycak, J. (2022). Regression via Gradient Descent. In Introduction to Algorithms and Machine Learning: from Sorting to Strategic Agents. https://justinmath.com/regression-via-gradient-descent/
Want to get notified about new posts? Join the mailing list and follow on X/Twitter.